|
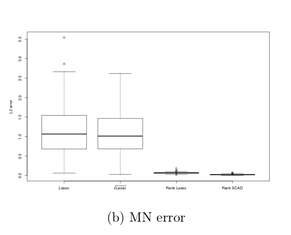
A tuning free robust and efficient approach to high-dimensional regressionWe introduce a novel approach for high-dimensional regression with theoretical guar- antees. The new procedure overcomes the challenge of tuning parameter selection of Lasso and possesses several appealing properties. It uses an easily simulated tuning parameter that automatically adapts to both the unknown random error distribution and the correlation structure of the design matrix. It is robust with substantial effi- ciency gain for heavy-tailed random errors while maintaining high efficiency for normal random errors. Comparing with other alternative robust regression procedures, it also enjoys the property of being equivariant when the response variable undergoes a scale transformation. Computationally, it can be efficiently solved via linear programming. Theoretically, under weak conditions on the random error distribution, we establish a finite-sample error bound with a near-oracle rate for the new estimator with the sim- ulated tuning parameter. Our results make useful contributions to mending the gap between the practice and theory of Lasso and its variants. We also prove that further improvement in efficiency can be achieved by a second-stage enhancement with some light tuning. Our simulation results demonstrate that the proposed methods often outperform cross-validated Lasso in various settings.
with Lan Wang, Runze Li, Yunan Wu and Bo Peng forthcoming (with discussion) in the Journal of the American Statistical Association: T&M |

|
Rejoinder for "A tuning free robust and efficient approach to high-dimensional regression"We heartily thank the Editors, Professors Regina Liu and Hongyu Zhao, for featuring
this paper and organizing stimulating discussions. We are grateful for the feedback on our work from the three distinguished discussants: Professors Jianqing Fan, Po-Ling Loh and Ali Shaojie. The discussants provide novel methods for inference, offer new applications such as graphical models and factor models, and highlight the possible impact of robust procedures in new domains. Their discussions have pushed forward robust high-dimensional statistics in disparate directions. These in-depth discussions with new contributions would easily qualify on their own as independent papers in the field of robust high-dimensional statistics. We sincerely thank the discussants for their time and effort in providing insightful comments and for their generosity in sharing their new findings. In the following, we organize our rejoinder around the major themes in the discussions. with Lan Wang, Runze Li, Yunan Wu and Bo Peng forthcoming in the Journal of the American Statistical Association: T&M |
|
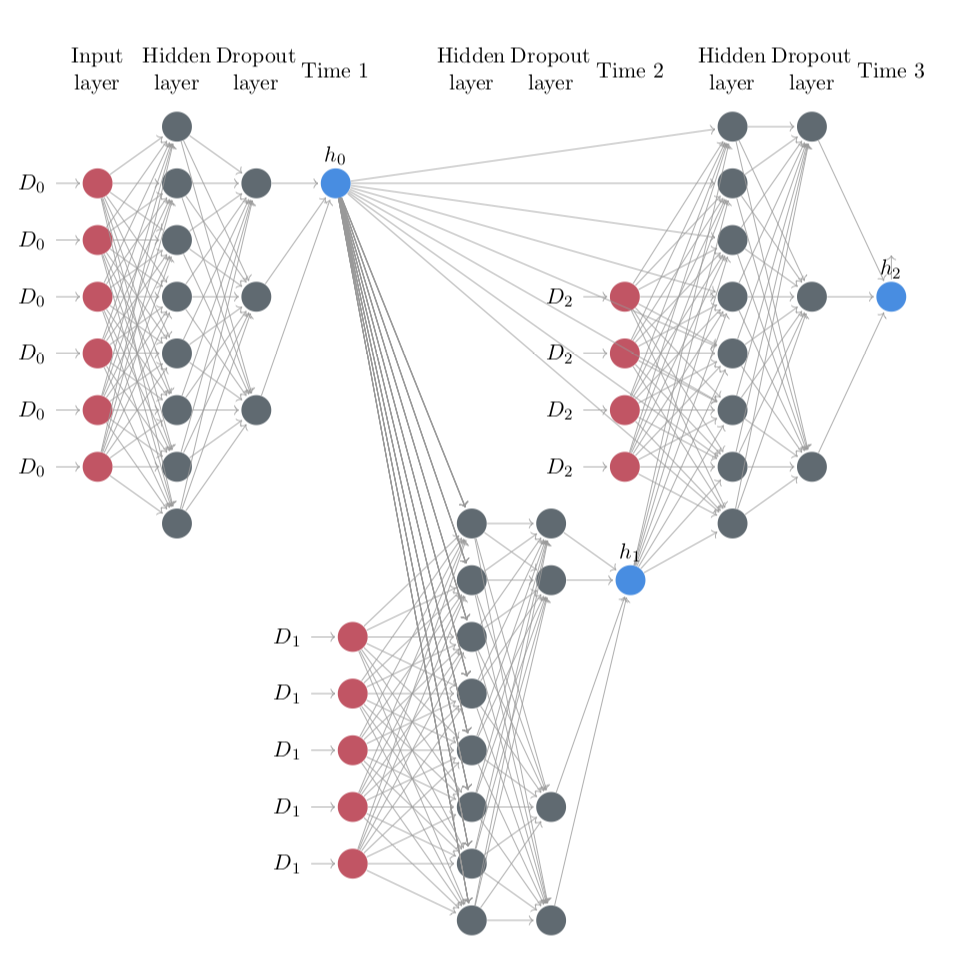
DeepHazard:
|

|
Detangling robustness in high dimensions:
|
|
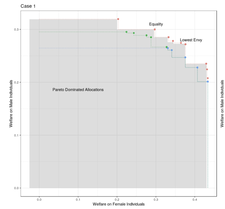
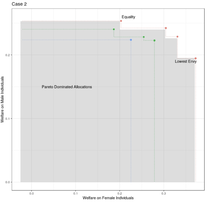
Fair Policy TargetingOne of the major concerns of targeting interventions on individuals in social welfare programs is discrimination: individualized treatments may induce disparities on sensitive attributes such as age, gender, or race. This paper addresses the question of the design of fair and efficient treatment allocation rules. We adopt the non-maleficence perspective of "first do no harm": we propose to select the fairest allocation within the Pareto frontier. We provide envy-freeness justifications to novel counterfactual notions of fairness. We discuss easy-to-implement estimators of the policy function, by casting the optimization into a mixed-integer linear program formulation. We derive regret bounds on the unfairness of the estimated policy function, and small sample guarantees on the Pareto frontier. Finally, we illustrate our method using an application from education economics.
with Davide Viviano submitted |
|
Minimax Semiparametric Learning With Approximate Sparsity Many objects of interest can be expressed as a linear, mean square continuous functional of a least squares projection (regression). Often the regression may be high dimensional, depending on many variables. This paper gives minimal conditions for root-n consistent and efficient estimation of such objects when the regression and the Riesz representer of the functional are approximately sparse and the sum of the absolute value of the coefficients is bounded. The approximately sparse functions we consider are those where an approximation by some t regressors has root mean square error less than or equal to Ct^{-ξ} for C, ξ>0. We show that a necessary condition for efficient estimation is that the sparse approximation rate ξ1 for the regression and the rate ξ2 for the Riesz representer satisfy max{ξ1,ξ2}>1/2. This condition is stronger than the corresponding condition ξ1+ξ2>1/2 for Holder classes of functions. We also show that Lasso based, cross-fit, debiased machine learning estimators are asymptotically efficient under these conditions. In addition we show efficiency of an estimator without cross-fitting when the functional depends on the regressors and the regression sparse approximation rate satisfies ξ1>1/2.
with Victor Chernozhukov, Whitney Newey and Yinchu Zhu submitted |
|
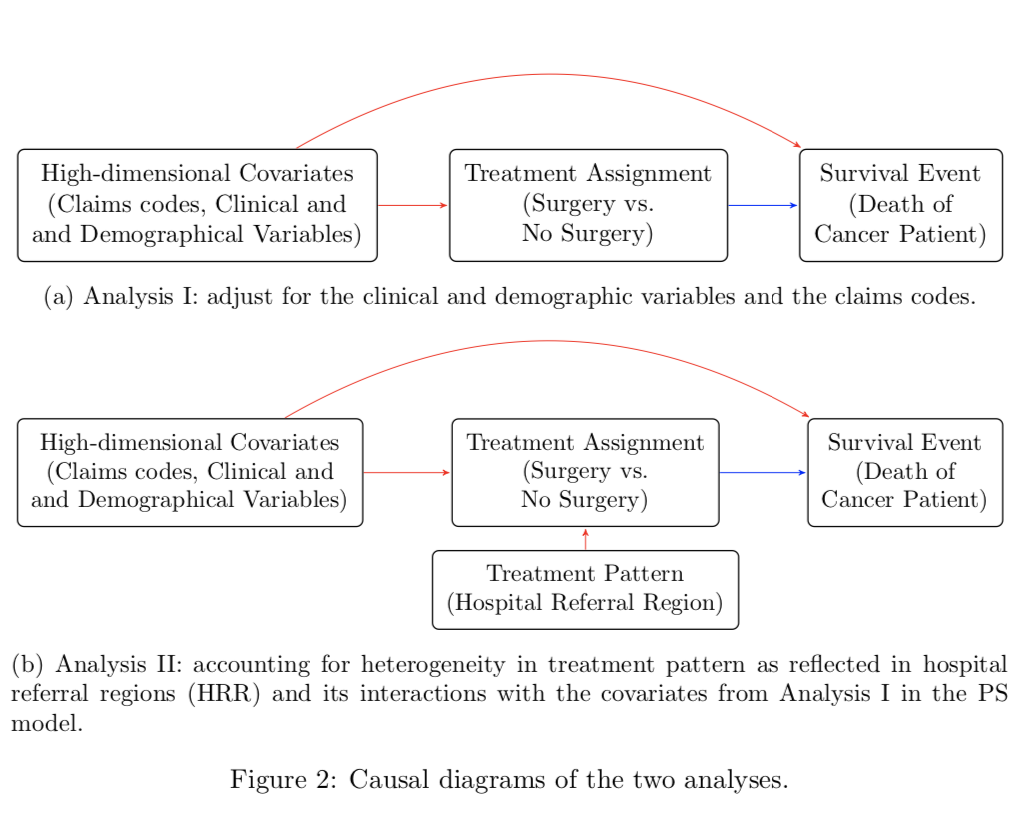
Estimating Treatment Effect under Additive Hazards Models with High-dimensional CovariatesEstimating causal effects for survival outcomes in the high-dimensional setting is an extremely important topic for many biomedical applications as well as areas of social sciences. We propose a new orthogonal score method for treatment effect estimation and inference that results in asymptotically valid confidence intervals assuming only good estimation properties of the hazard outcome model and the conditional probability of treatment. This guarantee allows us to provide valid inference for the conditional treatment effect under the high-dimensional additive hazards model under considerably more generality than existing approaches. In addition, we develop a new Hazards Difference (HDi) estimator. We showcase that our approach has double-robustness properties in high dimensions: with cross-fitting the HDi estimate is consistent under a wide variety of treatment assignment models; the HDi estimate is also consistent when the hazards model is misspecified and instead the true data generating mechanism follows a partially linear additive hazards model. We further develop a novel sparsity doubly robust result, where either the outcome or the treatment model can be a fully dense high-dimensional model. We apply our methods to study the treatment effect of radical prostatectomy versus conservative management for prostate cancer patients using the SEER-Medicare Linked Data.
with Jue Hou and Ronghui Xu revision at the Journal of the American Statistical Association: T&M |

|
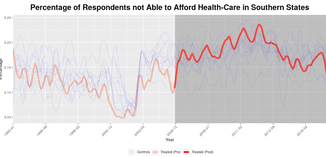
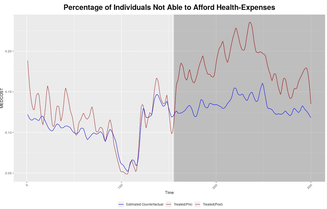
Sparsity Double Robust Inference of Average Treatment EffectsMany popular methods for building confidence intervals on causal effects under high-dimensional confounding require strong “ultra-sparsity” assumptions that may be difficult to validate in practice. To alleviate this difficulty, we here study a new method for average treatment effect estimation that yields asymptotically exact confidence in- tervals assuming that either the conditional response surface or the conditional proba- bility of treatment allows for an ultra-sparse representation (but not necessarily both). This guarantee allows us to provide valid inference for average treatment effect in high dimensions under considerably more generality than available baselines. In addition, we showcase that our results are semi-parametrically efficient.
with Stefan Wager and Yinchu Zhu submitted |
|
Synthetic Learner:
|
|
High-dimensional semi-supervised learning: in search of optimal inference of the meanWe provide a high-dimensional semi-supervised inference framework focused on the mean and variance of the response. Our data are comprised of an extensive set of observations regarding the covariate vectors and a much smaller set of labeled observations where we observe both the response as well as the covariates. We allow the size of the covariates to be much larger than the sample size and impose weak conditions on a statistical form of the data. We provide new estimators of the mean and variance of the response that extend some of the recent results presented in low-dimensional models. In particular, at times we will not necessitate consistent estimation of the functional form of the data. Together with estimation of the population mean and variance, we provide their asymptotic distribution and confidence intervals where we showcase gains in efficiency compared to the sample mean and variance. Our procedure, with minor modifications, is then presented to make important contributions regarding inference about average treatment effects. We also investigate the robustness of estimation and coverage and showcase widespread applicability and generality of the proposed method.
with Yuqian Zhang revision at Biometrika |
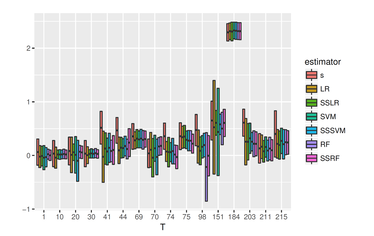
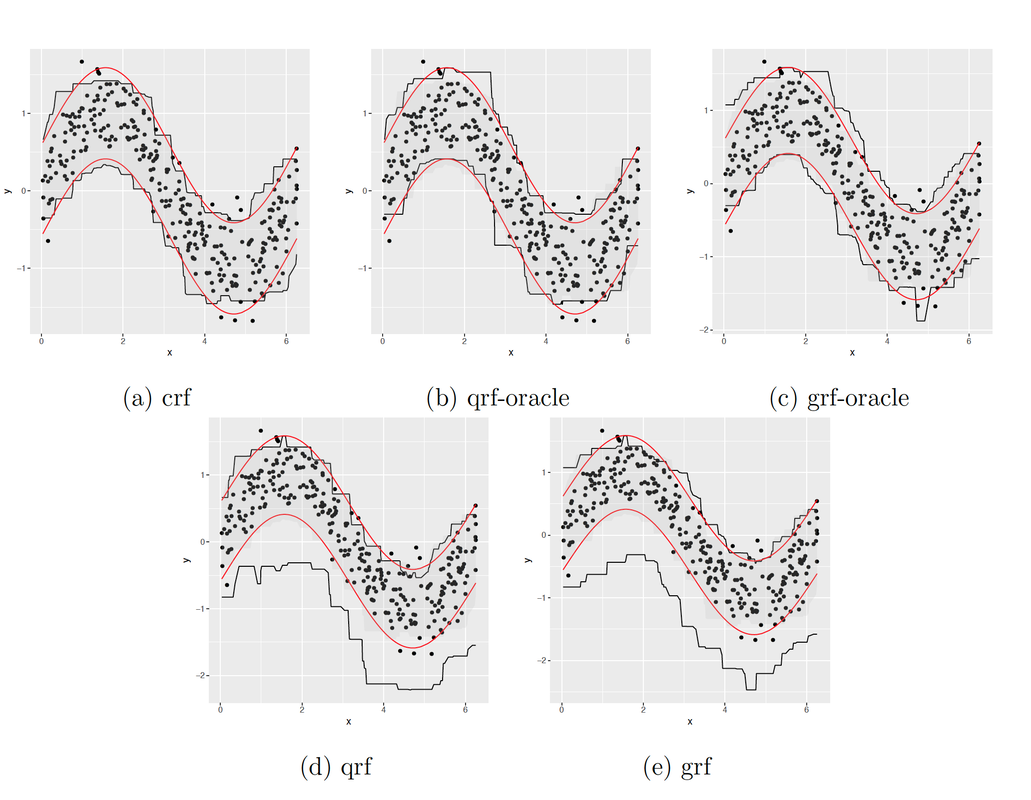
Censored quantile regression forests |
|
Random forests are powerful non-parametric regression method but are severely limited in their usage in the presence of randomly censored observations, and naively applied can exhibit poor predictive performance due to the incurred biases. Based on a local adaptive representation of random forests, we develop its regression adjustment for randomly censored regression quantile models. Regression adjustment is based on new estimating equations that adapt to censoring and lead to quantile score whenever the data do not exhibit censoring. The proposed procedure named {\it censored quantile regression forest}, allows us to estimate quantiles of time-to-event without any parametric modeling assumption. We establish its consistency under mild model specifications. Numerical studies showcase a clear advantage of the proposed procedure.
with Alexander Hanbo Li AISTATS 2020 |
|
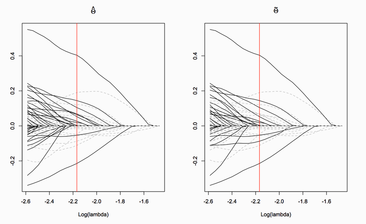
Confidence intervals for high-dimensional Cox modelThe purpose of this paper is to construct confidence intervals for the regression coefficients in high-dimensional Cox proportional hazards regression models where the number of covariates may be larger than the sample size. Our debiased estimator construction is similar to those in Zhang and Zhang (2014) and van de Geer et al. (2014), but the time-dependent covariates and censored risk sets introduce considerable additional challenges. Our theoretical results, which provide conditions under which our confidence intervals are asymptotically valid, are supported by extensive numerical experiments.
with Richard J. Samworth and Yi Yu to appear at Statistica Sinica |
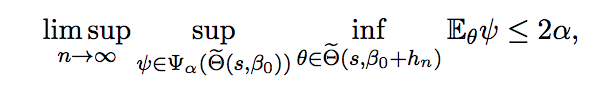
|
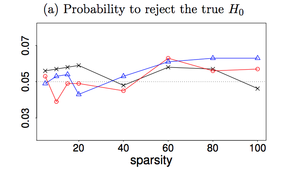
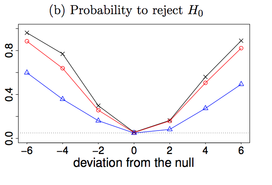
Testability of high-dimensional linear models with non-sparse structuresThis paper studies hypothesis testing and confidence interval construction in high-dimensional linear models with possible non-sparse structures. For a given component of the parameter vector, we show that the difficulty of the problem depends on the sparsity of the corresponding row of the precision matrix of the covariates, not the sparsity of the model itself. We develop new concepts of uniform and essentially uniform non-testability that allow the study of limitations of tests across a broad set of alternatives. Uniform non-testability identifies an extensive collection of alternatives such that the power of any test, against any alternative in this group, is asymptotically at most equal to the nominal size, whereas minimaxity shows the existence of one particularly "bad" alternative. Implications of the new constructions include new minimax testability results that in sharp contrast to existing results do not depend on the sparsity of the model parameters. We identify new tradeoffs between testability and feature correlation. In particular, we show that in models with weak feature correlations minimax lower bound can be attained by a confidence interval whose width has the parametric rate regardless of the size of the model sparsity.
with Jianqing Fan and Yinchu Zhu, major revision at AOS |
|
Testing in high-dimensional linear mixed models
Many scientific and engineering challenges -- ranging from pharmacokinetic drug dosage allocation and personalized medicine to marketing mix (4Ps) recommendations -- require an understanding of the unobserved heterogeneity in order to develop the best decision making-processes. In this paper, we develop a hypothesis test and the corresponding p-value for testing for the significance of the homogeneous structure in linear mixed models. A robust matching moment construction is used for creating a test that adapts to the size of the model sparsity. When unobserved heterogeneity at a cluster level is constant, we show that our test is both consistent and unbiased even when the dimension of the model is extremely high. Our theoretical results rely on a new family of adaptive sparse estimators of the fixed effects that do not require consistent estimation of the random effects. Moreover, our inference results do not require consistent model selection. We showcase that moment matching can be extended to nonlinear mixed effects models and to generalized linear mixed effects models. In numerical and real data experiments, we find that the developed method is extremely accurate, that it adapts to the size of the underlying model and is decidedly powerful in the presence of irrelevant covariates.
with Gerda Claeskens and Thomas Gueuning, to appear in the Journal of the American Statistical Association: T&M |

|
Fine-Gray competing risks model with high dimensional covariates: estimation and inferenceThe purpose of this paper is to construct confidence intervals for the regression coefficients in the Fine-Gray model for competing risks data with random censoring, where the number of covariates can be larger than the sample size. Despite strong motivation from biostatistics applications, high-dimensional Fine-Gray model has attracted relatively little attention among the methodological or theoretical literatures. We fill in this blank by proposing first a consistent regularized estimator and then the confidence intervals based on the one-step bias-correcting estimator. We are able to generalize the partial likelihood approach for the Fine-Gray model under random censoring despite many technical difficulties. We lay down a methodological and theoretical framework for the one-step bias-correcting estimator with the partial likelihood, which does not have independent and identically distributed entries. We also handle for our theory the approximation error from the inverse probability weighting (IPW), proposing novel concentration results for time dependent processes. In addition to the theoretical results and algorithms, we present extensive numerical experiments and an application to a study of non-cancer mortality among prostate cancer patients using the linked Medicare-SEER data.
with Ronghui Xu and Jue Hou, to appear at the Electronic Journal of Statistics |
|
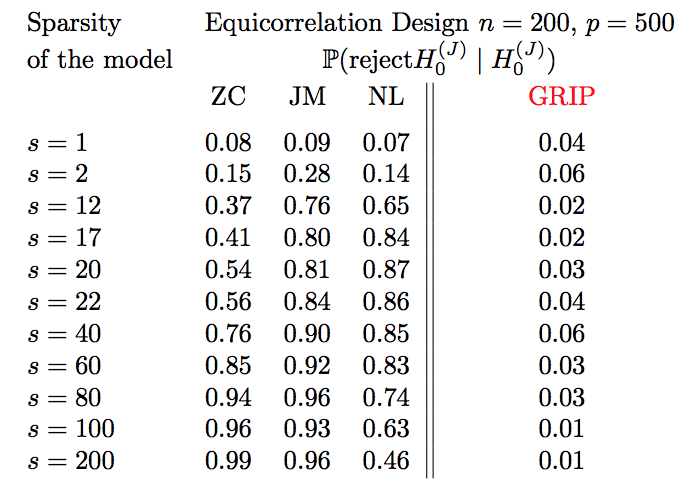
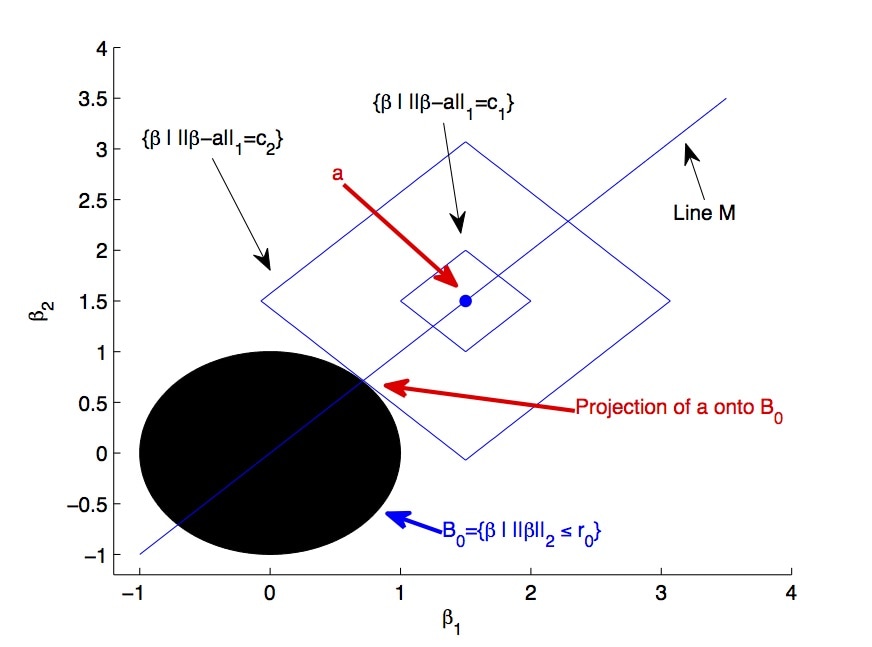
Breaking the curse of dimensionalityModels with many signals, high-dimensional models, often impose structures on the signal strengths. The common assumption is that only a few signals are strong and most of the signals are zero or close (collectively) to zero. However, such a requirement might not be valid in many real-life applications. In this article, we are interested in conducting large-scale inference in models that might have signals of mixed strengths. The key challenge is that the signals that are not under testing might be collectively non-negligible (although individually small) and cannot be accurately learned. This article develops a new class of tests that arise from a moment matching formulation. A virtue of these moment-matching statistics is their ability to borrow strength across features, adapt to the sparsity size and exert adjustment for testing growing number of hypothesis. GRoup-level Inference of Parameter, GRIP, test harvests effective sparsity structures with hypothesis formulation for an efficient multiple testing procedure. Simulated data showcase that GRIPs error control is far better than the alternative methods. We develop a minimax theory, demonstrating optimality of GRIP for a broad range of models, including those where the model is a mixture of a sparse and high-dimensional dense signals.
with Yinchu Zhu, revision requested by the Journal of the Machine Learning Research |
|
A projection pursuit framework for testing
|
|
Comment on "High dimensional
|
|
Uniform inference for high-dimensional
|

|
Two-sample testing in non-sparse
|
|
Linear hypothesis testing in dense
|
|
High-dimensional inference in linear models:
|
|
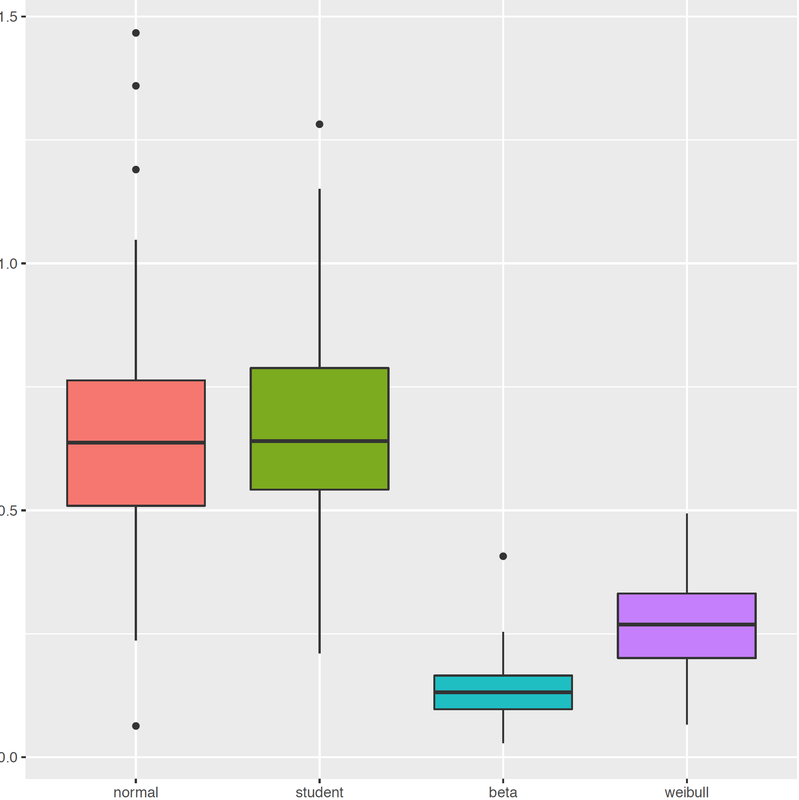
Generalized M-estimators for high-dimensional Tobit I modelsThis paper develops robust confidence intervals in high-dimensional and left-censored regression. Type-I censored regression models are extremely common in practice, where a competing event makes the variable of interest unobservable. However, techniques developed for entirely observed data do not directly apply to the censored observations. In this paper, we develop smoothed estimating equations that augment the de-biasing method, such that the resulting estimator is adaptive to censoring and is more robust to the misspecification of the error distribution. We propose a unified class of robust estimators, including Mallow's, Schweppe's and Hill-Ryan's one-step estimator. In the ultra-high-dimensional setting, where the dimensionality can grow exponentially with the sample size, we show that as long as the preliminary estimator converges faster than n^{-1/4}, the one-step estimator inherits asymptotic distribution of fully iterated version. Moreover, we show that the size of the residuals of the Bahadur representation matches those of the simple linear models, s^{3/4 } (\log (p \vee n))^{3/4} / n^{1/4} -- that is, the effects of censoring asymptotically disappear. Simulation studies demonstrate that our method is adaptive to the censoring level and asymmetry in the error distribution, and does not lose efficiency when the errors are from symmetric distributions. Finally, we apply the developed method to a real data set from the MAQC-II repository that is related to the HIV-1 study.
with Jiaqi Guo, Electronic Journal of Statistics, (2019), 13(1), p. 582-645. |
|
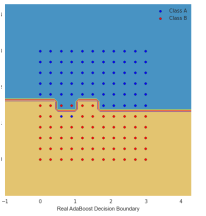
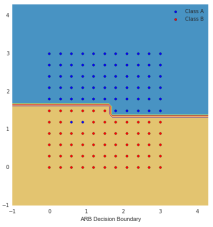
Boosting in the presence of outliers:
|
|
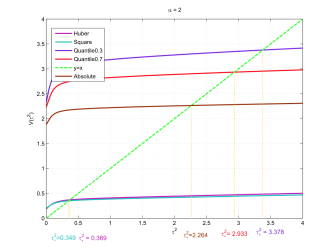
Robustness in sparse linear models:
|
|
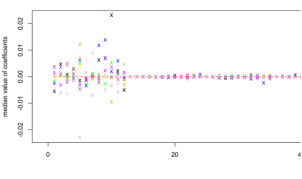
Randomized Maximum Contrast Selection:
|
|
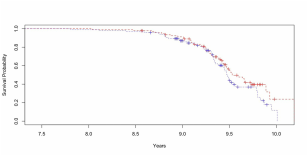
Structured Estimation in NonParametric Cox ModelIn this paper, we study theoretical properties of the non-parametric Cox proportional hazards model in a high dimensional non-asymptotic setting. We establish the finite sample oracle l2 bounds for a general class of group penalties that allow possible hierarchical and overlapping structures. We approximate the log partial likelihood with a quadratic functional and use truncation arguments to reduce the error. Unlike the existing literature, we exemplify differences between bounded and possibly unbounded non-parametric covariate effects. In particular, we show that bounded effects can lead to prediction bounds similar to the simple linear models, whereas unbounded effects can lead to larger prediction bounds. In both situations we do not assume that the true parameter is necessarily sparse. Lastly, we present new theoretical results for hierarchical and smoothed estimation in the non-parametric Cox model. We provide two examples of the proposed general framework: a Cox model with interactions and an ANOVA type Cox model.
with Rui Song, Electronic Journal of Statistics (2015), 9(1), p.492-534 |

|
Cultivating Disaster Donors Using Data AnalyticsNon-profit organizations use direct-mail marketing to cultivate one-time donors and convert them into recurring contributors. Cultivated donors generate much more revenue than new donors, but also lapse with time, making it important to steadily draw in new cultivations. We propose a new empirical model based on importance subsample aggregation of a large number of penalized logistic regressions. We show via simulation that a simple design strategy based on these insights has potential to improve success rates from 5.4% to 8.1%.
with Ilya Ryzhov and Bin Han, Management Science (2016), 62 (3), p. 849-866 |
|
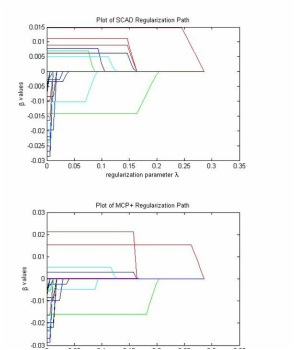
Regularization for Cox's proportional
|

|
Composite Quasi-Likelihood
|